- 已编辑
配置:
cpu:3A6000
内存:16G
硬盘:256G
显卡:“龙芯牌独立显卡”
未使用显卡加速,纯cpu计算生成。
技术框架
Ollama + deepseek-r1
由于ollama官网不提供LoongArch架构的二进制包,所以需要手工编译ollama,然后直接起ollama服务,pull相应的大模型即可进入对话。
笔者采用的系统环境是aosc
PRETTY_NAME="AOSC OS (12.0.4)"
NAME="AOSC OS"
VERSION_ID="12.0.4"
VERSION="12.0.4 (localhost)"
BUILD_ID="20250122"
ID=aosc
ANSI_COLOR="1;36"
HOME_URL="https://aosc.io/"
SUPPORT_URL="https://github.com/AOSC-Dev/aosc-os-abbs"
BUG_REPORT_URL="https://github.com/AOSC-Dev/aosc-os-abbs/issues"准备编译环境
安装基本开发环境
sudo oma install build-essential
安装go和python环境
sudo oma install go python cmake
如果您的系统环境是rpm系的,请参考以下命令:
yum groupinstall 'Development Tools' # y + enter
yum install cmake go python g++下载ollama代码
wget -c https://github.com/ollama/ollama/archive/refs/heads/main.zip
解压代码
unzip main.zip 
开始编译
加速go
export GO111MODULE=on
export GOPROXY=https://goproxy.io
开始构建ollama
cd ollama-main
go generate ./...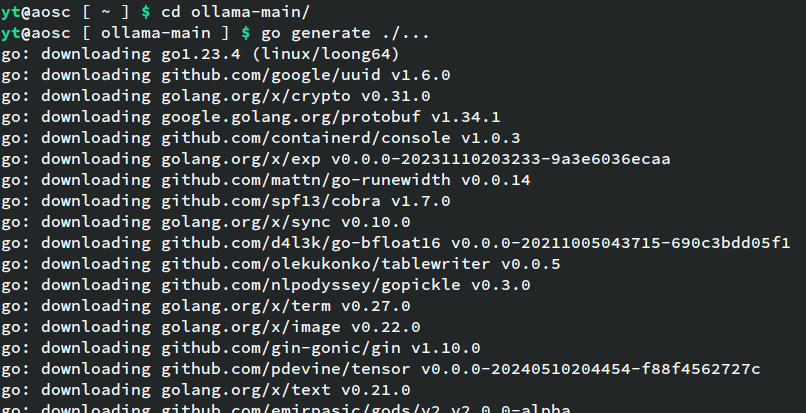
go build -p 8 .等待编译完成,会在当前目录生成可执行二进制文件ollama。

起ollama服务
./ollama serve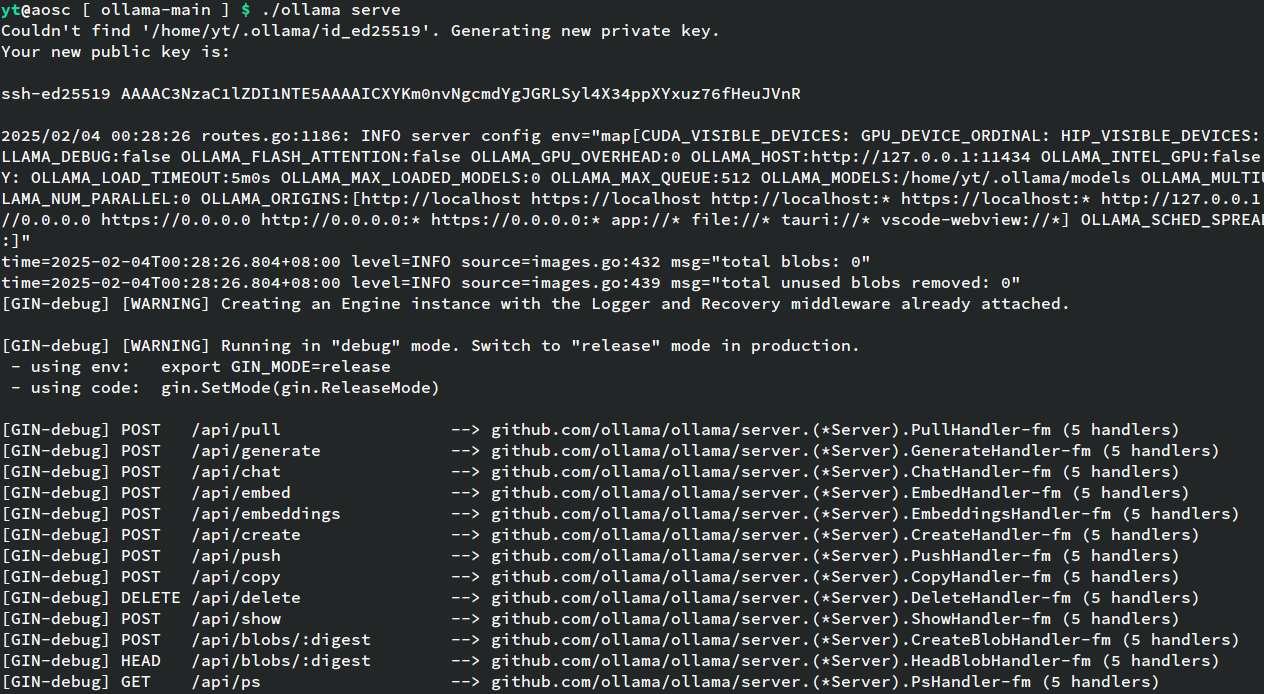
pull deepseek-r1大模型
到以下网站选择不同参数的大模型
https://ollama.com/library/deepseek-r1:7b
参数越多,需要的内存越多,消耗的内存基本等于对应大模型自身的大小。
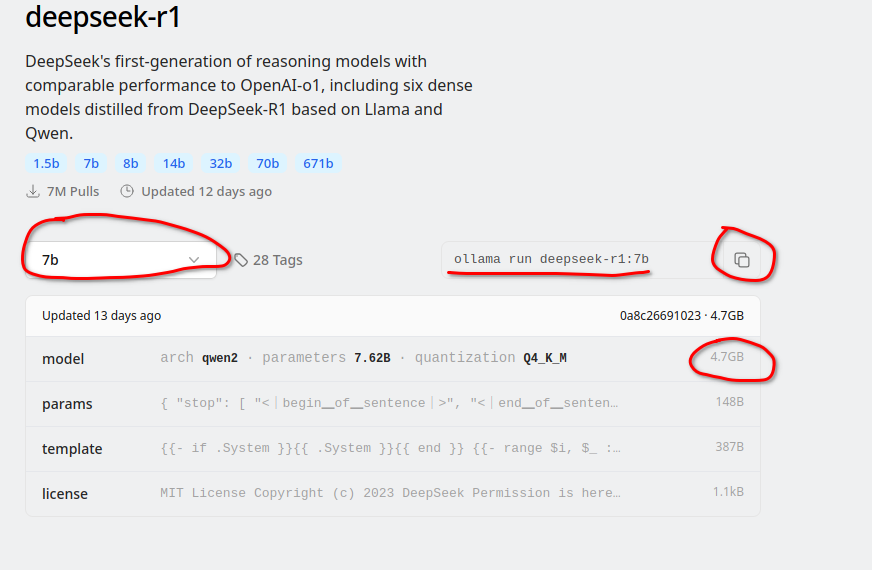
我这里选择默认的7b
./ollama run deepseek-r1:7b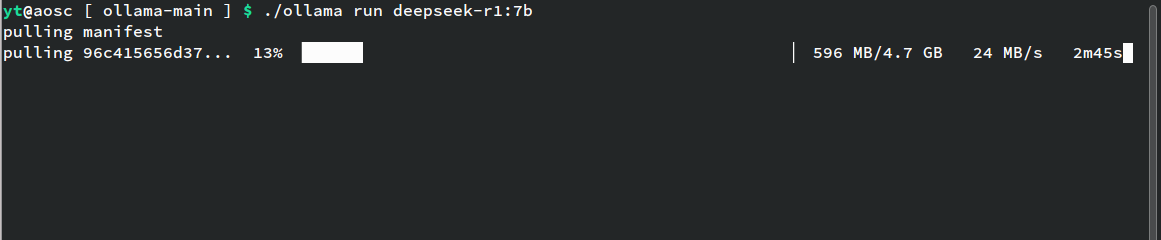
开始玩耍
等待下载校验完成后,自动进入对话模式,开始提问:
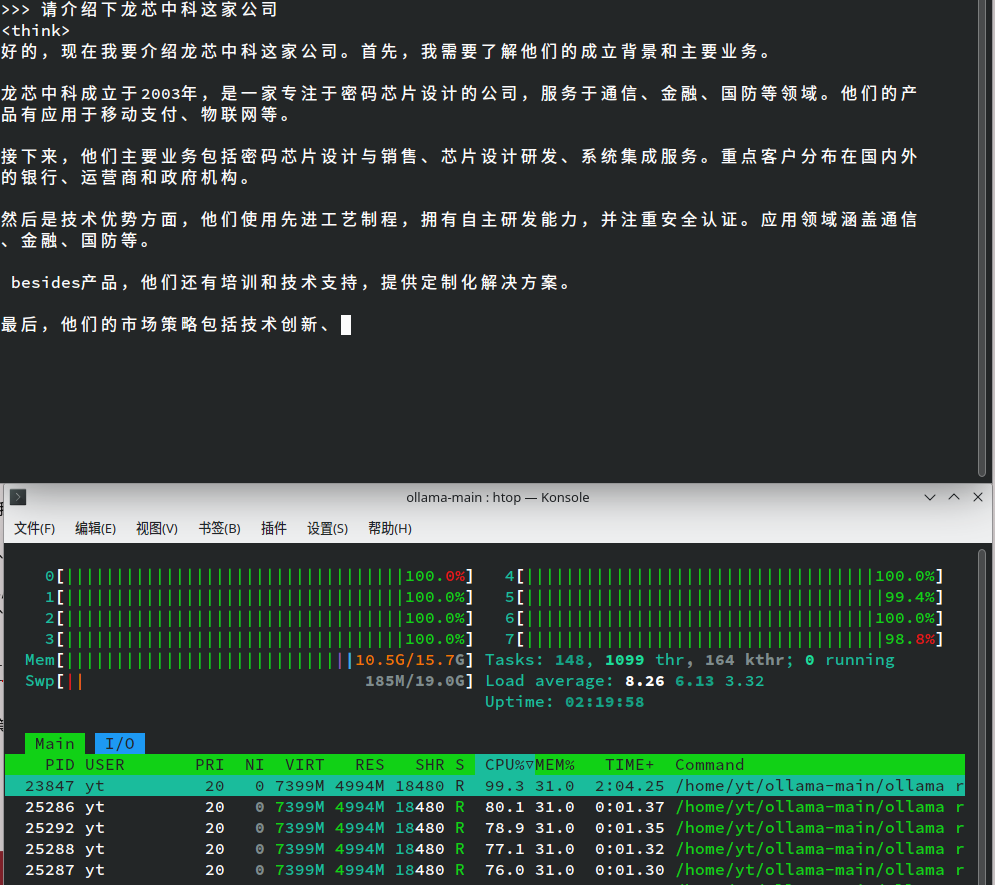
生成速度平均一秒一个字,祝大家玩的愉快!